この記事は Go Advent Calendar 2020 14日目 の記事です。
みなさん Go してますか?
Spanner も触ってますか?
最近やっと部分的に本番環境で Spanner を利用し始めました。
Spanner のスキーマなどを git で管理しつつ、チーム内でレビューなどをしつつ運用する方法として、
以下のツールたちを利用しています。
試したツールたち
最終的に利用しているツールは
となっていますが、以下のイメージで利用しています。
全体の関係
以下の図のような関係になっています。
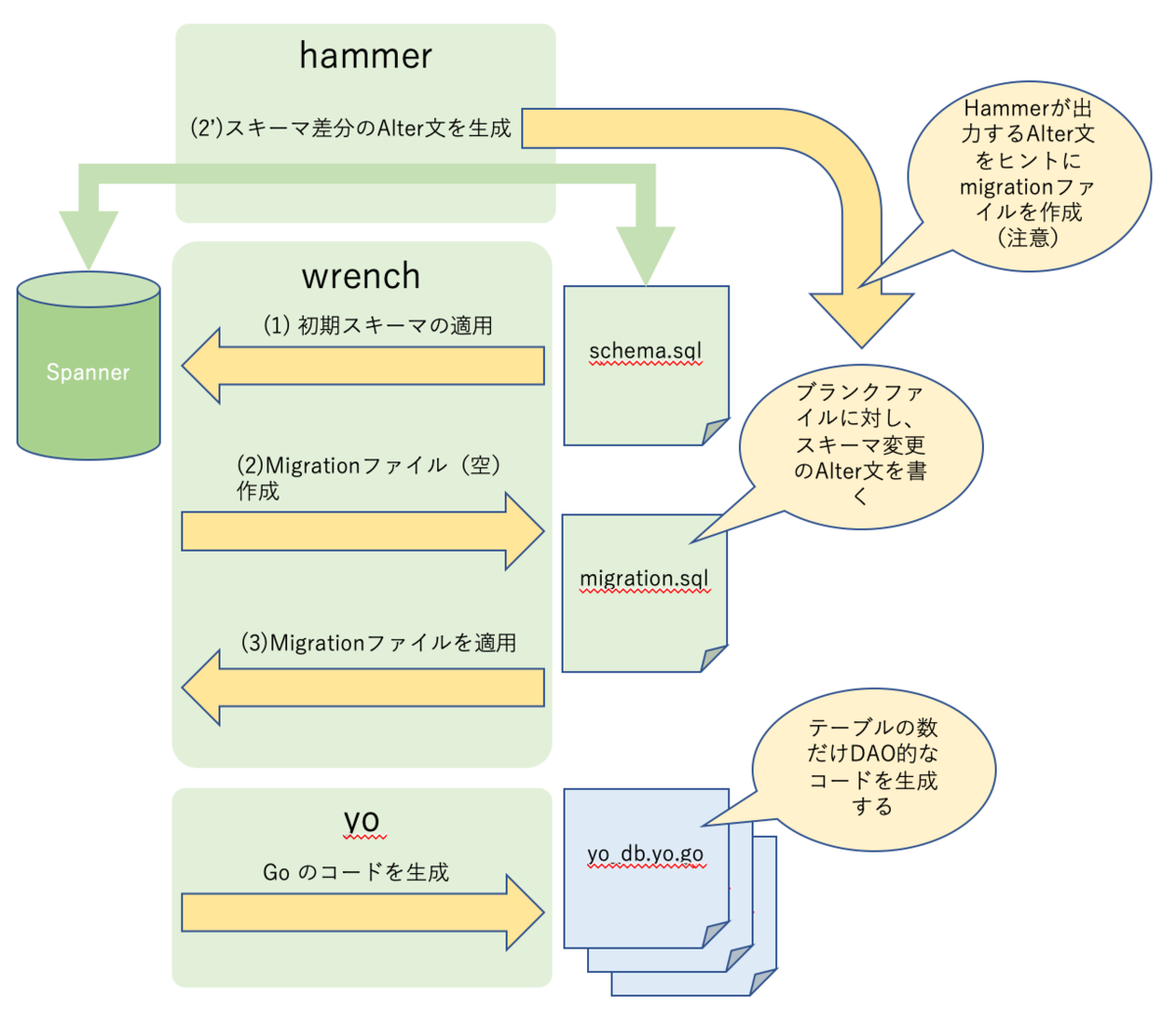
1. DB の初期スキーマを適用する
wrench を利用します。
事前に schema.sql など、スキーマファイルを作成しておきます。
最終的には yo がスキーマの定義をみて Mutation を生成するコードを生成するので、
検索の条件にする必要があるカラムなどは適切にインデックスを付与するなどします。
SQLでは自由にかけてしまいますが、単純な利用方法であれば、インデックスを貼らないカラムに対する条件で検索ができるようなコードはかけなくなるので安全とも言えるかもしれません。
コマンドは
wrench create --directory {DDLファイルがおいてあるディレクトリ}
という感じで実行します。
2. 開発中にカラムに変更がある場合にはマイグレーションを行う
wrench で以下のコマンドを実行すると、マイグレーション用のファイルが生成されます
wrench migrate create --directory ./
コマンドを実行するとファイルが生成されますが、連番のブランクファイルになっています。
そのファイルに alter 文を記述し、カラムの変更を適用するイメージになります。
ここの alter 文を hammer を利用しようとしましたがちょっとうまくいきませんでした。(図の2')
3. miigration ファイルを DB に適用する
これも wrench を利用します。
以下のコマンドで適用します。
wrench migrate up --directory {DDLファイルが置いてあるディレクトリ}
4. 開発のためのコードを DB のスキーマから生成する
yo というツールを利用します。
以下のコマンドを実行します
yo $(SPANNER_PROJECT_ID) $(SPANNER_INSTANCE_ID) $(SPANNER_DATABASE_ID) -o {生成したコードを格納したいディレクトリ}
wrench は project_id, instance_id, database_id は環境変数で渡していましたが、 yo は直接コマンドラインで渡します。
生成されるファイルは
- yo_db.yo.go
- {table_name}.yo.go
が最低限生成されます。
生成されたファイルは .yo.go になるので、自動生成されたコードをファイル名から容易に判別できます。
おまけ1
Go のアドベントカレンダーなので、Go コードを出さねば・・・と思ったので...
Spanner の Go クライアントは内部的にセッションプールの仕組みを持っています。
以下のような雰囲気で設定を行います。
const healthCheckIntervalMins = 50
const numChannels = 4
var config = spanner.ClientConfig{
SessionPoolConfig: spanner.SessionPoolConfig{
MinOpened: 100,
MaxOpened: numChannels * 100,
MaxBurst: 10,
WriteSessions: 0.2,
HealthCheckWorkers: 10,
HealthCheckInterval: healthCheckIntervalMins * time.Minute,
},
}
一度、Spanner を利用したアプリケーションを検証環境にデプロイしてテストしていた際に、
ある程度リクエストを受けるとなぜか Spanner がブロックし、アプリケーションが全く応答しなくなるという問題にぶち当たりました。
数百のリクエストを投げると、ある時からリクエストが全部タイムアウトして、全くサーバが動いている様子がない、
というなかなか恐ろしいものでした。
原因としては、 ReadOnlyTransaction() で取得したトランザクション(connection?)は、 defer で Close() しないとプールの中の Connection が枯渇して ReadOnlyTransaction() がブロックし続けるというものでした。
おまけ2
おまけ1で得た知見。
zagane (https://github.com/gcpug/zagane) を使いましょう!
zagane は以下を防いでくれます
unstopiter: it finds iterators which did not stop.
unclosetx: it finds transactions which does not close
wraperr: it finds (*spanner.Client).ReadWriteTransaction calls which returns wrapped errors
自分の使い方が悪いのか、モノレポ構造で使っているのが悪いのか、
極稀に検知してくれないケースが自分の環境では有るのですが、これは Spanner を利用するなら必須と言っても良いものです。
まとめ
と、ここまで書きましたが、実際には既存の Datastore から単純に一部移行したぐらいでしか利用できていません・・><
数百リクエスト/秒 ぐらいで利用しているので、CPU 負荷も 5% も行かないぐらいでめちゃくちゃ安定して稼働してます。Spannerすごい。
なんかもっと書きたいことがあったような気がするけど書いているうちに忘れてしまった・・・ま、いっか
明日の記事は hajimehoshi さんの 「Go におけるアラビア語描画について」 です。楽しみですね。
ではでは。









